groupby |
您所在的位置:网站首页 › group by › groupby |
groupby
|
In this Pandas group by we are going to learn how to organize Pandas dataframes by groups. More specifically, we are going to learn how to group by one and multiple columns. Furthermore, we are going to learn how calculate some basics summary statistics (e.g., mean, median), convert Pandas groupby to dataframe, calculate the percentage of observations in each group, and many more useful things. 在这个熊猫小组中,我们将学习如何按组组织熊猫数据帧。 更具体地说,我们将学习如何按一列和多列分组。 此外,我们将学习如何计算一些基本摘要统计信息(例如,均值,中位数),将Pandas groupby转换为数据框,计算每个组中观察值的百分比以及更多有用的东西。 More about working with Pandas: Pandas Dataframe Tutorial 有关使用Pandas的更多信息: Pandas Dataframe教程First of all we are going to import pandas as pd, and read a CSV file, using the read_csv method, to a dataframe. In the example below, we use index_col=0 because the first row in the dataset is the index column. 首先,我们将以pd格式导入熊猫,并使用read_csv方法将CSV文件读取到数据框。 在下面的示例中,我们使用index_col = 0,因为数据集中的第一行是索引列。 import pandas as pd data_url = 'http://vincentarelbundock.github.io/Rdatasets/csv/carData/Salaries.csv' df = pd.read_csv(data_url, index_col=0) df.head()We used Pandas head to se the first 5 rows of our dataframe. In the image above we can see that we have, at least, three variables that we can group our data by. That is, we can group our data by “rank”, “discipline”, and “sex”. Of course, we could also group it by yrs.since.phd or yrs.service but it may be a lot of groups. As previously mentioned we are going to use Pandas groupby to group a dataframe based on one, two, three, or more columns. 我们使用Pandas head来获取数据帧的前5行。 在上图中,我们可以看到至少有三个变量可以对数据进行分组。 也就是说,我们可以按“等级”,“学科”和“性别”对数据进行分组。 当然,我们也可以按yrs.since.phd或yrs.service对其进行分组,但可能会有很多分组。 如前所述,我们将使用Pandas groupby根据一,二,三或更多列对数据帧进行分组。 Data can be loaded from other file formats as well (e.g., Excel, HTML, JSON): 数据也可以从其他文件格式(例如Excel,HTML,JSON)加载: Pandas Excel Tutorial: How to Read and Write Excel FilesExplorative Data Analysis with Pandas, SciPy, and Seaborn includes a short introduction to Pandas read_html Pandas Excel教程:如何读取和写入Excel文件 使用Pandas,SciPy和Seaborn进行的探索性数据分析包括对Pandas的简短介绍read_html Python Pandas Groupby示例 (Python Pandas Groupby Example)We are starting with the simplest example; grouping by one column. In the Pandas groupby example below we are going to group by the column “rank”. 我们从最简单的例子开始; 按一列分组。 在下面的Pandas groupby示例中,我们将按“等级”列进行分组。 There are many different methods that we can use on Pandas groupby objects (and Pandas dataframe objects). All available methods on a Python object can be found using this code: 我们可以对Pandas groupby对象(和Pandas dataframe对象)使用许多不同的方法。 可以使用以下代码找到Python对象上的所有可用方法: import IPython # Grouping by one factor df_rank = df.groupby('rank') # Getting all methods from the groupby object: meth = [method_name for method_name in dir(df_rank) if callable(getattr(df_rank, method_name)) & ~method_name.startswith('_')] # Printing the result print(IPython.utils.text.columnize(meth))
Note, that in the code example above we also import IPython to print the list in columns. In the following examples we are going to use some of these methods. First, we can print out the groups by using the groups method to get a dictionary of groups: 请注意,在上面的代码示例中,我们还导入了IPython以按列打印列表。 在以下示例中,我们将使用其中一些方法。 首先,我们可以使用groups方法打印组,以获取组字典: df_rank.groups
We can also use the groupby method get_group to filter the grouped data. In the next code example we are going to select the Assistant Professor group (i.e., “AsstProf”). 我们还可以使用groupby方法get_group过滤分组的数据。 在下一个代码示例中,我们将选择“助理教授”组(即“ AsstProf”)。 # Get group df_rank.get_group('AsstProf').head()
熊猫Groupby Count (Pandas Groupby Count) If we want to find out how big each group is (e.g., how many observations in each group), we can use use .size() to count the number of rows in each group: 如果我们想找出每个组的大小(例如,每个组中有多少个观测值),可以使用.size()来计算每个组中的行数: df_rank.size() # Output: # # rank # AssocProf 64 # AsstProf 67 # Prof 266 # dtype: int64
Additionally, we can also use Pandas groupby count method to count by group(s) and get the entire dataframe. If we don’t have any missing values the number should be the same for each column and group. Thus, this is a way we can explore the dataset and see if there are any missing values in any column. 此外,我们还可以使用Pandas的groupby count方法按组进行计数并获取整个数据框。 如果我们没有任何缺失值,则每个列和每个组的编号应相同。 因此,这是一种我们可以浏览数据集并查看任何列中是否缺少任何值的方法。 df_rank.count()
That was how to use Pandas size to count the number of rows in each group. We will return to this, later, when we are grouping by multiple columns. Now we are going to In some cases we may want to find out the number of unique values in each group. This can be done using the groupby method nunique: 这就是使用熊猫大小来计算每个组中的行数的方法。 稍后,当我们按多列分组时,我们将返回到此。 现在,在某些情况下,我们可能想要找出每个组中唯一值的数量。 这可以使用groupby方法nunique来完成: df_rank.nunique()
As can be seen in the the last column (salary) there are 63 Associate Professors, 53 Assistant Proffessors, and 261 Professors in the dataset. In this example we have a complete dataset and we can see that some have the same salary (e.g., there are 261 unique values in the column salary for Professors). As we will see if we have missing values in the dataframe we would get a different result. In the next example we are using Pandas mask method together with NumPy’s random.random to insert missing values (i.e., np.NaN) in 10% of the dataframe: 从最后一栏(薪水)可以看出,数据集中有63位副教授,53位助理教授和261位教授。 在此示例中,我们具有完整的数据集,我们可以看到其中一些具有相同的薪水(例如,“教授”列中的薪水有261个唯一值)。 我们将看到如果数据框中缺少值,我们将得到不同的结果。 在下一个示例中,我们将Pandas遮罩方法与NumPy的random.random一起使用,以在10%的数据帧中插入缺失值(即np.NaN): df_null = df.mask(np.random.random(df.shape) < .1) df_null.isnull().sum().reset_index(name='N Missing Values')
Note, we used the reset_index method above to get the multi-level indexed grouped dataframe to become a single indexed. In the particular example, above, we used the parameter name to name the count column (“N Missing Values”). This parameter, however, can only be used on Pandas series objects and not dataframe objects. 注意,我们使用了上面的reset_index方法来获取多级索引分组数据帧,使其成为单个索引。 在上面的特定示例中,我们使用参数名称来命名计数列(“ N个缺失值”)。 但是,此参数只能在Pandas系列对象上使用,而不能在dataframe对象上使用。 That said, let’s return to the example; if we run the same code as above (counting unique values by group) we can see that it will not count missing values: 就是说,让我们回到例子。 如果我们运行与上面相同的代码(按组计算唯一值),我们可以看到它不会计算缺失值: df_null.groupby('rank').nunique()
That is, we don’t get the same numbers in the two tables because of the missing values. In the following examples we are going to work with Pandas groupby to calculate the mean, median, and standard deviation by one group. 也就是说,由于缺少值,我们在两个表中没有得到相同的数字。 在以下示例中,我们将与Pandas groupby一起计算一组的均值,中位数和标准差。 熊猫Groupby Mean (Pandas Groupby Mean)If we want to calculate the mean salary grouped by one column (rank, in this case) it’s simple. We just use Pandas mean method on the grouped dataframe: 如果要计算按一列分组的平均工资(在这种情况下为等级),这很简单。 我们只对分组数据框使用熊猫均值法: df_rank['salary'].mean().reset_index()
Having a column named salary may not be useful. For instance, if someone else are going to see the table they may not know that it’s the mean salary for each group. Luckily, we can add the rename method to the above code to rename the columns of the grouped data: 具有名为薪水的列可能没有用。 例如,如果其他人要看表,他们可能不知道这是每个组的平均工资。 幸运的是,我们可以在上面的代码中添加重命名方法来重命名分组数据的列: df_rank['salary'].mean().reset_index().rename( columns={'rank':'Rank','salary' : 'Mean Salary'})
在熊猫中使用groupby方法得出的组的中位数 (Median Score of a Group Using the groupby Method in Pandas) Now lets group by disciplne of the academic and find the median salary in the next Pandas groupby example 现在让学者按学科分组,并在下一个熊猫分组示例中找到工资中位数 df.groupby('rank')['salary'].median().reset_index().rename( columns={'rank':'Rank','salary' : 'MedianSalary'})
使用Pandas Groupby按组汇总数据 (Aggregate Data by Group using Pandas Groupby) Most of the time we want to have our summary statistics in the same table. We can calculate the mean and median salary, by groups, using the agg method. In this next Pandas groupby example we are also adding the minimum and maximum salary by group (rank): 大多数时候,我们希望将汇总统计信息放在同一张表中。 我们可以使用agg方法按组计算平均工资和中位数工资。 在下一个Pandas groupby示例中,我们还将按组(排名)添加最低和最高薪水: df_rank['salary'].agg(['mean', 'median', 'std', 'min', 'max']).reset_index()
A very neat thing with Pandas agg method is that we can write custom functions and pass them along. Let’s say that we wanted, instead of having one column for min salary and one column for max salary, to have a column with salary range: 使用Pandas agg方法的一件非常整洁的事情是,我们可以编写自定义函数并将其传递。 假设我们想要的是,而不是有一栏用于最低薪水,而一栏用于最高薪水,而不是有一栏的薪水范围: def salary_range(df): mini = df.min() maxi = df.max() rang = '%s - %s' % (mini, maxi) return rang df_descriptive = df_rank['salary'].agg(['mean', 'median', 'std', salary_range]).reset_index()
Here, however, the output will have the name of the methods/functions used. That is, we will have a column named ‘salary_range’ and we are going to rename this column: 但是,此处的输出将具有所用方法/功能的名称。 也就是说,我们将有一个名为“ salary_range”的列,我们将重命名该列: # Renaming Pandas Dataframe Columns df_descriptive.rename(columns={'rank':'Rank', 'mean':'Mean', 'median':'Median', 'std':'Standard Deviation', 'salary_range':'Range'})
Furthermore, it’s possible to use methods from other Python packages such as SciPy and NumPy. For instance, if we wanted to calculate the harmonic and geometric mean we can use SciPy: 此外,可以使用其他Python软件包中的方法,例如SciPy和NumPy。 例如,如果我们要计算谐波和几何平均值,则可以使用SciPy: from scipy.stats.mstats import gmean, hmean df_descriptive = df_rank['salary'].agg(['mean', 'median', hmean, gmean]).reset_index() df_descriptiveMore about doing descriptive statistics using Pyton: 有关使用Pyton进行描述性统计的更多信息: Descriptive Statistics using Python and PandasHow to do Descriptive Statistics in Python using Numpy 使用Python和Pandas进行描述性统计 如何使用Numpy在Python中进行描述性统计 熊猫分组比多列 (Pandas Groupby Multiple Columns)In this section we are going to continue using Pandas groupby but grouping by many columns. In the first example we are going to group by two columns and the we will continue with grouping by two columns, ‘discipline’ and ‘rank’. To use Pandas groupby with multiple columns we add a list containing the column names. In the example below we also count the number of observations in each group: 在本节中,我们将继续使用Pandas groupby,但将按许多列进行分组。 在第一个示例中,我们将按两列分组,而我们将继续按“纪律”和“排名”两列进行分组。 要将Pandas groupby与多个列一起使用,我们添加一个包含列名的列表。 在下面的示例中,我们还计算每组中的观察次数: df_grp = df.groupby(['rank', 'discipline']) df_grp.size().reset_index(name='count')
Again, we can use the get_group method to select groups. However, in this case we have to input a tuple and select two groups: 同样,我们可以使用get_group方法选择组。 但是,在这种情况下,我们必须输入一个元组并选择两个组: # Get two groups df_grp.get_group(('AssocProf', 'A')).head()
熊猫Groupby计算多个组 (Pandas Groupby Count Multiple Groups) In the next groupby example we are going to calculate the number of observations in three groups (i.e., “n”). We have to start by grouping by “rank”, “discipline” and “sex” using groupby. As with the previous example (groupby one column) we use the method size to calculate the n and reset_index, with the parameter name=”n”, to get the series to a dataframe: 在下一个分组示例中,我们将计算三组(即“ n”)中的观察数。 我们必须首先使用groupby按“等级”,“纪律”和“性别”分组。 与前面的示例(groupby一列)一样,我们使用方法大小来计算n和reset_index(参数名称为“ n”),以将序列获得数据框: df_3grps = df.groupby(['rank', 'discipline', 'sex']) df_n_per_group = df_3grps.size().reset_index(name='n')Now we can continue and calculate the percentage of men and women in each rank and discipline. In this, and the next, Pandas groupby example we are going to use the apply method together with the lambda function. 现在,我们可以继续计算每个级别和学科中男女的比例。 在此以及下一个Pandas groupby示例中,我们将结合使用apply方法和lambda函数。 perc = df.groupby(['rank', 'discipline', 'sex'])['salary'].size() # Give the percentage on the level of Rank: percbyrank = perc.groupby(level=0).apply(lambda x: 100 * x / float(x.sum())) print(percbyrank) print('Total percentage in group AssocProf. ', percbyrank.reset_index().query('rank == "AssocProf"')['salary'].sum())
Note, in the last line of code above we calculate the total of % for the group AssocProf and it’s 100, which is good. We are going to continue with calculating the percentage of men and women in each group (i.e., rank and discipline). In the next code we have to summarize the total n (n=397). We can, for instance, see that there are more male professors regardless of discipline. 请注意,在上面的代码的最后一行中,我们计算了AssocProf组的百分比总数,它是100,这很好。 我们将继续计算每个组中男性和女性的百分比(即等级和纪律)。 在下一个代码中,我们必须总结总计n (n = 397)。 例如,我们可以看到,无论纪律如何,都有更多的男教授。 n = perc.reset_index()['salary'].sum() totalperc = perc.groupby(level=0).apply(lambda x: 100 * x / N).reset_index(name='% of total n') totalperc.reset_index()如何将Pandas Groupby转换为Dataframe (How to convert a Pandas groupby to Dataframe) When dealing with multiple groups and Pandas groupby we get a GroupByDataFrame object. Let’s use type to see what type a grouped object have: 当处理多个组和Pandas groupby时,我们得到一个GroupByDataFrame对象。 让我们使用type来查看分组对象的类型: df_rn = df.groupby(['rank', 'discipline']).mean()Furthermore, if we use the index method we can see that it is MultiIndex: 此外,如果使用index方法,我们可以看到它是MultiIndex: df_rn.index
It’s easy to convert the Pandas groupby to dataframe; we have actually already done it. In this example, however, we are going to calculate the mean values per the three groups. Furthermore, we are going to add a suffix to each column and use reset_index to get a dataframe. 将Pandas groupby转换为数据框很容易; 我们实际上已经做到了。 但是,在此示例中,我们将计算这三个组的平均值。 此外,我们将为每列添加一个后缀,并使用reset_index获取数据框。 df_rn = df_rn.add_suffix('_Mean').reset_index() type(df_rn) # Output: pandas.core.frame.DataFrame熊猫groupby agg与多个组 (Pandas groupby agg with Multiple Groups) In this last section we are going use agg, again. We are not going into detail on how to use mean, median, and other methods to get summary statistics, however. This is because it’s basically the same as for grouping by n groups and it’s better to get all the summary statistics in one table. 在最后一部分中,我们将再次使用agg。 但是,我们不会详细介绍如何使用均值,中位数和其他方法来获取摘要统计信息。 这是因为它基本上与按n个组分组相同,并且最好将所有摘要统计信息聚集在一个表中。 That is, we are going to calculate mean, median, and standard deviation using the agg method. In this groupby example we are also adding the summary statistics (i.e., “mean”, “median”, and “std”) to each column. Otherwise we will get a multi-level indexed result like the image below: 也就是说,我们将使用agg方法计算平均值,中位数和标准差。 在此groupby示例中,我们还将摘要统计信息(即“均值”,“中位数”和“ std”)添加到每一列。 否则,我们将获得多级索引结果,如下图所示: 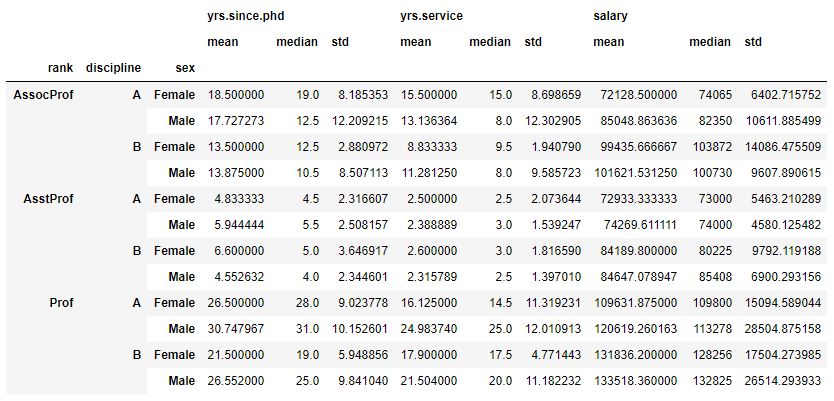
If we use Pandas columns and the method ravel together with list comprehension we can add the suffixes to our column name and get another table. Note, in the example code below we only print the first 7 columns. In fact, with many columns it may be better to keep the result multi-level indexed. 如果我们将Pandas列和ravel方法与列表理解一起使用,则可以将后缀添加到我们的列名中并获得另一个表。 注意,在下面的示例代码中,我们仅打印前7列。 实际上,对于许多列,最好将结果保留为多级索引。 df_stats = df.groupby(['rank', 'discipline', 'sex']).agg(['mean', 'median', 'std']) df_stats.columns = ["_".join(x) for x in df_stats.columns.ravel()] df_stats.iloc[:,0:6].reset_index()
Note, if we wanted an output as the first image we just remove the second line above (“df_stats.columns = …”). Additionally, as previous mentioned, we can also use custom functions, NumPy and SciPy methods when working with groupby agg. Just scroll back up and look at those examples, for grouping by one column, and apply them to the data grouped by multiple columns. More information of the different methods and objects used here can be found in the Pandas documentation. 注意,如果我们希望将输出作为第一张图像,则只需删除上面的第二行(“ df_stats.columns =…”)。 此外,如前所述,在使用groupby agg时,我们还可以使用自定义函数NumPy和SciPy方法。 只需向上滚动并查看这些示例(按一列分组),然后将其应用于按多列分组的数据即可。 有关此处使用的不同方法和对象的更多信息,请参见Pandas文档 。 结论: (Conclusion:)In this Pandas groupby tutorial we have learned how to use Pandas groupby to: 在此Pandas groupby教程中,我们学习了如何使用Pandas groupby进行以下操作: group one or many columnscount observations using the methods count and sizecalculate simple summary statistics using: groupby mean, median, stdgroupby agg (aggregate)agg with our own function Calculate the percentage of observations in different groups 分组一列或多列 使用计数和大小方法计数观察值 使用以下方法计算简单的摘要统计信息: groupby平均值,中位数,标准 groupby agg(汇总) 用我们自己的功能 计算不同组中观察值的百分比翻译自: https://www.pybloggers.com/2018/12/python-pandas-groupby-tutorial/ |
【本文地址】
今日新闻 |
点击排行 |
|
推荐新闻 |
图片新闻 |
|
专题文章 |